How Smart Speakers Know You're Talking to Them After a Command
This patent describes how a smart speaker system can tell if follow-up speech is meant for it, even without a "wake word," by analyzing voice activity and partial speech recognition results using an AI model.
Original patent title: “Detecting system-directed speech”
This patent describes how a smart speaker system can tell if follow-up speech is meant for it, even without a "wake word," by analyzing voice activity and partial speech recognition results using an AI model. Granted to Amazon Technologies in 2022 with 21 claims and 64 forward citations, and it is expected to expire in 2037.
Key facts
Coverage
What does this patent actually cover?
The patent details a method for a system, like a smart speaker, to identify if incoming speech is directed at it, especially after an initial interaction. First, the system receives an first command, processes it, and responds. Crucially, it then instructs the device to send subsequent audio without requiring a wake word (ClaimclaimA numbered sentence at the end of a patent that legally defines what the inventor owns. The most important section.Read more → 1). When this second audio arrives, the system first checks for voice activity. Then, it performs automatic speech recognition (ASR) on the audio. While ASR is running, it simultaneously creates a "feature vector" from the early parts of the ASR results and feeds this into a deep neural network (DNN). This DNN calculates a score indicating how likely the speech is intended for the system. If the score passes a certain level, the system proceeds to understand the full speech and act on it. For example, after you say "Alexa, set a timer for 10 minutes," the system might then listen for a follow-up like "and add a reminder for my meeting" without needing you to say "Alexa" again.
The gap
What does this patent NOT cover?
- Does not cover systems that always require a wake word for every interaction.
- Does not cover systems that rely solely on voice activity detection to determine system-directed speech.
- Does not cover determining system-directed speech without using a deep neural network on a feature vector derived from partial ASR results.
- Does not cover systems where the device itself determines the presence of a wake word in the second input audio data (ClaimclaimA numbered sentence at the end of a patent that legally defines what the inventor owns. The most important section.Read more → 1 explicitly states "without the device determining a presence of a wakeword").
- Does not cover systems that only use full ASR results, rather than partial ASR results, to create the feature vector for the DNN.
These exclusions are unique to PatentBrief — derived from the actual claim language, not patent-office boilerplate.
What made this novel
The innovation lies in using partial ASR results, combined with other audio characteristics, to predict if speech is system-directed in parallel with the main ASR process. This allows the system to quickly decide whether to fully process the speech or discard it, saving computational resources and improving responsiveness for follow-up commands.
The Patent Drawing
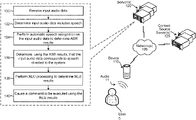
Schematic visualization of the patent's claim structure. Hand-drawn diagrams in progress for each landmark patent.
Where you've seen this
Real-world examples
Amazon Alexa's "Follow-Up Mode"
Google Assistant's "Continued Conversation"
Most modern smart speaker follow-up interactions
Why it matters
The bigger picture
This technology is fundamental for creating more natural and conversational interactions with voice assistants. It allows users to have follow-up conversations without repeatedly saying the wake word, making the experience smoother and less clunky. This capability is key to the user experience of modern smart speakers and virtual assistants, enabling multi-turn dialogues.
Filed
September 1, 2017
Granted
June 14, 2022
Market context
Who's building on this
Companies in this space
Amazon, as the assigneeassigneeThe entity that owns the patent — usually the inventor's employer or a company.Read more →, continues to develop and integrate this type of technology into its Alexa ecosystem. Google and Apple also implement similar "continued conversation" or "follow-up" features in their respective voice assistants, Google Assistant and Siri, to enhance user experience.
Market impact
This patent's technology has significantly improved the naturalness of interactions with voice assistants. It moved the industry beyond rigid "wake word for every command" models, enabling more fluid, conversational experiences. This capability is now a standard expectation for premium voice assistant products, fostering greater user engagement and wider adoption of smart devices.
Claim 1 — Plain English
What this patent covers
The patent details a method for a system, like a smart speaker, to identify if incoming speech is directed at it, especially after an initial interaction. First, the system receives an first command, processes it, and responds. Crucially, it then instructs the device to send subsequent audio without requiring a wake word (Claim 1). When this second audio arrives, the system first checks for voice activity. Then, it performs automatic speech recognition (ASR) on the audio. While ASR is running, it simultaneously creates a "feature vector" from the early parts of the ASR results and feeds this into a deep neural network (DNN). This DNN calculates a score indicating how likely the speech is intended for the system. If the score passes a certain level, the system proceeds to understand the full speech and act on it. For example, after you say "Alexa, set a timer for 10 minutes," the system might then listen for a follow-up like "and add a reminder for my meeting" without needing you to say "Alexa" again.
The clever bit
The innovation lies in using partial ASR results, combined with other audio characteristics, to predict if speech is system-directed in parallel with the main ASR process. This allows the system to quickly decide whether to fully process the speech or discard it, saving computational resources and improving responsiveness for follow-up commands.
What it does not cover
- Does not cover systems that always require a wake word for every interaction.
- Does not cover systems that rely solely on voice activity detection to determine system-directed speech.
- Does not cover determining system-directed speech without using a deep neural network on a feature vector derived from partial ASR results.
- Does not cover systems where the device itself determines the presence of a wake word in the second input audio data (Claim 1 explicitly states "without the device determining a presence of a wakeword").
- Does not cover systems that only use full ASR results, rather than partial ASR results, to create the feature vector for the DNN.
Patent timeline
Application submitted to the patent office
Application published, typically 18 months after filing
Patent officially issued
Patent enters public domain
PatentBrief Score
Impact Score
High impact
Citation count
36/40
Highly cited
Claim breadth
14/20
Broad claimsclaimsThe numbered statements at the end of a patent that legally define what the inventor owns.Read more →
Recency
20/20
Granted within 5 years
Assignee scale
20/20
Major company or institution
PatentBrief Impact Score — based on citation count, claim breadth, recency, and assignee scale. Not a legal assessment.
Heuristic Value Estimate
What this patent might be worth
$293K – $936K
Midpoint $585K · 11.2 yr remaining · industry ×1.5
Heuristic only — blends forward/backward citation counts, claim scope, time remaining, litigation history, and CPC-derived industry baseline. Real valuations need a professional appraisal.
The original legal language
Original claims
21 claims as filed with the patent office.
Concepts involved
Citations
Patent lineage
Cite this patent
Matsoukas, S., Mallidi, S. H. R., Hoffmeister, B., & Maas, R. M. R. (2022). How Smart Speakers Know You're Talking to Them After a Command (U.S. Patent No. 11,361,763). U.S. Patent and Trademark Office. https://patentbrief.org/patent/us/11361763/detecting-system-directed-speech
Auto-generated from the patent record. Double-check author order and the issue date against the official USPTO document before submitting.
Embed
Add this patent to your site
Drop this plain-English patent card into any blog post or article — free, no signup. It always links back to the full breakdown here.
<div data-patentlens-widget data-patent-number="US11361763"></div> <script src="https://patentbrief.org/embed.js" async></script>
Stay in the loop
Get a weekly digest of new patents.
One email per week. No spam. Unsubscribe anytime.
Keep exploring
Related patents you should know
US 4683195 · 1987
How to Make Billions of Copies of a DNA Segment
This patent describes the Polymerase Chain Reaction (PCR), a method to rapidly create many copies of a specific piece of DNA or RNA, enabling its detection and analysis.
Cetus Corp
US 8697359 · 2014
How to Edit Genes in Human Cells Using an Engineered CRISPR System
This patent describes an engineered CRISPR-Cas9 system for precisely cutting DNA in eukaryotic cells to change how genes work, opening the door for gene editing in complex organisms.
Massachusetts Institute of Technology
US 7657849 · 2010
How the iPhone's Slide-to-Unlock Gesture Works
Apple's 2010 patent describes unlocking a device by dragging a specific graphical image across the touchscreen along a predefined path, a gesture that became iconic with the original iPhone.
Apple Inc
US 4733665 · 1988
How Doctors Implant a Permanent Stent Using a Balloon
This patent describes the method for placing a permanent, expandable wire mesh tube inside a blood vessel or other body tube using a balloon-tipped catheter to widen it and keep it open.
Expandable Grafts Partnership
US 4965188 · 1990
How to Make Many Copies of a DNA Piece with Heat
This patent describes the Polymerase Chain Reaction (PCR) method, a technique to make millions of copies of a specific DNA segment using a heat-resistant enzyme and repeated temperature changes.
Cetus Corp
US 4235871 · 1980
How to Encapsulate Active Materials in Lipid Bubbles Efficiently
This patent describes a method for trapping biologically active substances inside tiny, multi-layered fat bubbles called liposomes, using a specific water-in-oil emulsion and gel-forming process to improve how much material gets captured.
Individual
Semantically similar
You might also find these interesting
US 9548050 · 2017 · Apple Inc
How a Digital Assistant Launches Apps Using Your Voice
US 11204787 · 2021 · Apple Inc
How Digital Assistants Control Apps and Ask for More Information
US 9965247 · 2018 · Sonos Inc
How Sonos Speakers Use Personalized Wake Words to Recognize Different Users
US 8521818 · 2013 · Solariat Inc
How Software Detects What You Want Based on Your Social Media Posts
More to explore
More in Consumer Electronics
US 7657849 · 2010 · Apple Inc
How the iPhone's Slide-to-Unlock Gesture Works

US 7479949 · 2009 · Apple Inc
How Touchscreens Understand Your Finger Swipes and Scrolls

US 4528643 · 1985 · FPDC Inc
How Stores Make Custom Products On-Demand with Remote Approval

US 7469381 · 2008 · Apple Inc
How Touchscreens Show and Snap Back When You Scroll Past an Edge
New to patents?
Common Questions
Frequently Asked Questions
What does How Smart Speakers Know You're Talking to Them After a Command cover?
This patent describes how a smart speaker system can tell if follow-up speech is meant for it, even without a "wake word," by analyzing voice activity and partial speech recognition results using an AI model.
Who owns patent US 11361763?
Amazon Technologies owns this patent, granted in 2022.
When does this patent expire?
This patent is expected to expire on September 1, 2037, when the invention enters the public domain.
What is patent US 11361763 cited by?
This patent has been cited by 64 later patents that build on its ideas.
What problem does this patent solve?
This technology is fundamental for creating more natural and conversational interactions with voice assistants. It allows users to have follow-up conversations without repeatedly saying the wake word, making the experience smoother and less clunky. This capability is key to the user experience of modern smart speakers and virtual assistants, enabling multi-turn dialogues.
What does this patent NOT cover?
Does not cover systems that always require a wake word for every interaction.
Same assignee
More from Amazon Technologies
Patent monitoring